728x90
Transformer 모델
: 기존 인코더-디코더 모델을 발전시킨 모델로, RNN 기반 인코더-디코더 모델보다 학습이 빠르고 성능이 좋다.
- 병렬화
- RNN 기반 인코더-디코더: 입력으로 들어오는 텍스트의 단어들을 순차적으로 계산하여 인코딩.
- Transformer: 행렬곱으로 한 번에 병렬 처리.

Positional encoding
- (RNN 사용 X) 순차 입력을 받지 않음 → 위치/순서 정보를 제공해줘야 한다.
- Positional encoding: 인코더 및 디코더의 입력 값마다 상대적인 위치 정보를 더하는 기술.
- Transformer는 단순 비트 인코딩이 아니라 Sin, Cos 함수를 사용한 positional encoding을 사용한다.
- 장점
- Sin, Cos 함수) Positional encoding 값이 항상 -1에서 1사이의 값으로 나온다.
- 학습 데이터의 가장 긴 문장보다 더 긴 문장이 실제 운용 중에 들어와도 positional encoding이 에러없이 상대적인 encoding값을 줄 수 있다.
- 각 단어의 word embedding에 positional encoding을 더해준 다음, Self-Attention 연산을 수행한다.
Encoder
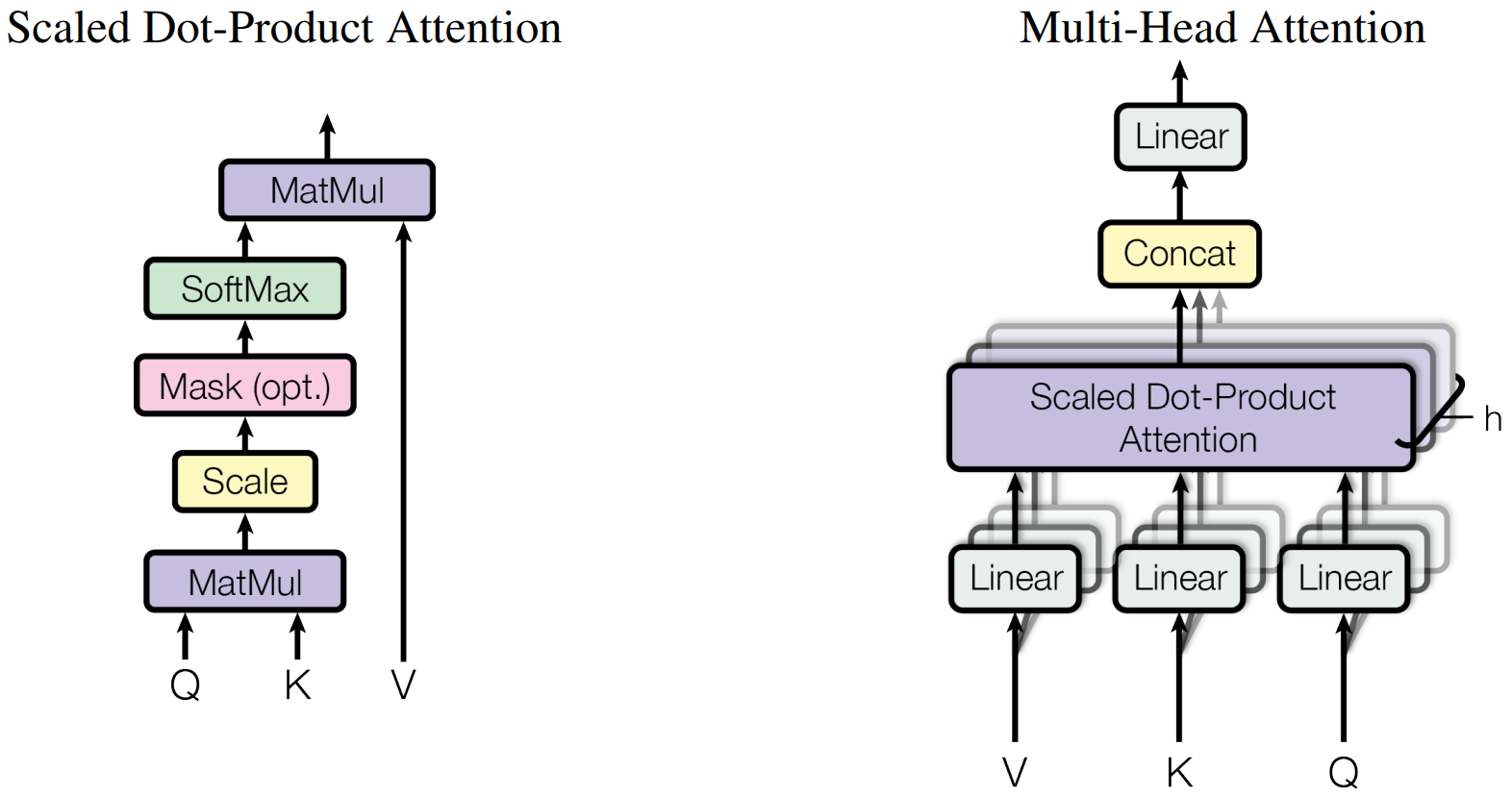
- Self-Attention
- K, Q, V
- Scaled Dot-Product Attention: Attention score 계산.
- 점수에 따라 가중치 부여.
- Attention score = Query * Key
- softmax(attention score / sqrt(Dk)): attention score를 확률로 변환
- Query와 Key 연관성: 단어 간의 연관성
- Multi Head Attention
- Transformer는 8개(h=8) Attention를 병렬로 수행한다.
- 각 헤드는 독립적으로 다른 가중치 매트릭스를 사용한다. → 각 헤드가 다른 정보를 집중하도록 유도
- 문장이 모호할 경우, 한 개의 attention으로 이 모호한 정보를 충분히 encoding하기 어렵기 때문에 multi-head attention을 사용해서 되도록 연관된 정보를 다른 관점에서 수집해서 이 점을 보완할 수 있다.
- Concat: 가중치가 부여된 임베딩들을 하나로 합친다.
- Transformer는 8개(h=8) Attention를 병렬로 수행한다.
더보기
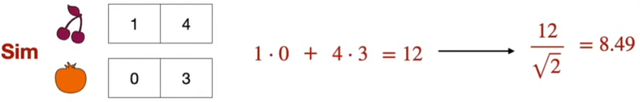
Scaled Dot-Product
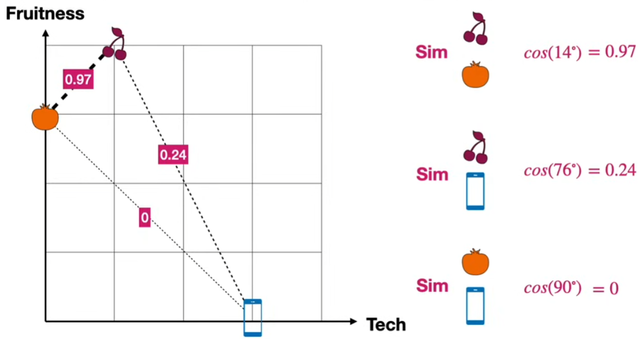
- Similarity
- word 간 유사성
- distance
- Measure
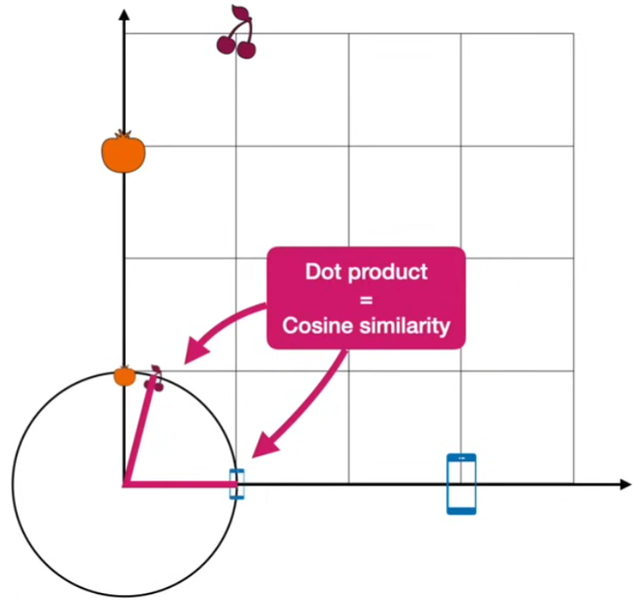
- Dot product
- Cosine similarity: dot product와 유사
- 각도를 이용함.
- 1에 가까울수록 높은 similarity
- 길이가 1인 vector의 경우, dot product와 cosine similarity는 똑같다!
- Scaled dot product
- dot product divided by the square root of the length of the vector
- very long vector ⇒ very large dot product ⇒ want these numbers to be small ⇒ divide by the square root of the length of the vectors
- dot product divided by the square root of the length of the vector
Encoder의 전반적인 구조
- 단어를 word embedding으로 변환한 후에 positional encoding을 적용한다.
- multi-head attention에 입력한다.
- multi-head attention을 통해 출력된 여러 결과 값들을 모두 이어 붙여 또 다른 행렬과 곱해 결국 최초의 word embedding과 동일한 차원을 갖는 벡터로 출력되게 한다.
- 각 벡터는 따로 Fully-Connected layer로 들어가서 입력과 동일한 차원의 벡터로 출력된다.
- Residual Connection: 입력된 값을 다시 한 번 더 해주어 정보 손실을 보완한다.
- Layer normalizaiton: 학습 효율 증진
Encoder layer의 입력 벡터와 출력 벡터의 차원이 같다. => Encoder layer를 여러 개 이어붙여 사용할 수 있다.
- 6개의 encoder layer 구성. (N=6)
Decoder

- 6개 decoder layer로 구성. (N=6)
- 최초 단어부터 끝 단어까지 순차적으로 단어를 출력.
- Masked Multi-Head Self-Attention
- decoder layer에서 지금까지 출력된 값들에 attention을 적용한다.
- 아직 출력되지 않은 미래의 단어에 attention을 적용하면 안 됨.
- decoder layer에서 지금까지 출력된 값들에 attention을 적용한다.
- Multi head attention
- encoder의 MHA와 달리, 현재 디코더의 입력 값을 query로 사용하고 encoder의 최종 출력 값을 key와 value로 사용한다.
- 인코더의 출력에서 중요한 정보를 key와 value로 획득해서 디코더의 다음 단어로 가장 적합한 단어를 출력하는 과정.
- encoder와 마찬가지로, Feed forward layer를 통해 최종값을 vector로 출력한다.
- encoder의 MHA와 달리, 현재 디코더의 입력 값을 query로 사용하고 encoder의 최종 출력 값을 key와 value로 사용한다.
- decoder의 최종단
- Linear layer -> Softmax layer
- 모델이 알고 있는 모든 단어들에 대한 확률값을 출력.
- 가장 높은 확률을 지닌 값이 바로 “다음 단어”가 된다!
- Label smoothing 적용하여 성능 향상
- Linear layer -> Softmax layer
Transformer 기반 모델
Autoencoder Transformers
- 차원 축소(dimensionality reduction), feature learning에 탁월.
- BERT (Bidirectional Encoder Representations from Transformers)
- 입력 문장의 양방향 맥락을 이해하여 문장 내 단어 관계를 파악.
- 마스킹된 단어를 예측하여 학습.
Autoregressive Transformers
- 이전 토큰을 조건화하여 시퀀스에서 다음 토큰 예측.
- 언어 모델링 및 기타 생성 작업에 널리 사용됨.
- GPT-3 (Generative Pre-trained Transformer 3)
- 시퀀스 내 이전 토큰을 기반으로 다음 토큰 예측
Sequence-to-Sequence Transformers
- input sequences → output sequences 매핑이 필요한 tasks에 사용됨
- T5 (Text-to-Text Transformer)
- 모든 NLP 작업을 text-to-text 형식으로 변환
LLM/Transformer 발전 양상
현재 NLP 모델의 거의 대부분이 Transformer 구조를 기반으로 하며, 모델의 용도에 따라 Transformer의 Encoder, Decoder를 개별 또는 통합 사용하는 추세를 보인다.
→ Transformer의 발전 양상이 곧 LLM의 발전 양상으로 이어진다.
LLM의 발전 양상
: Decoder(-only) 중심으로 빠른 발전을 보임.
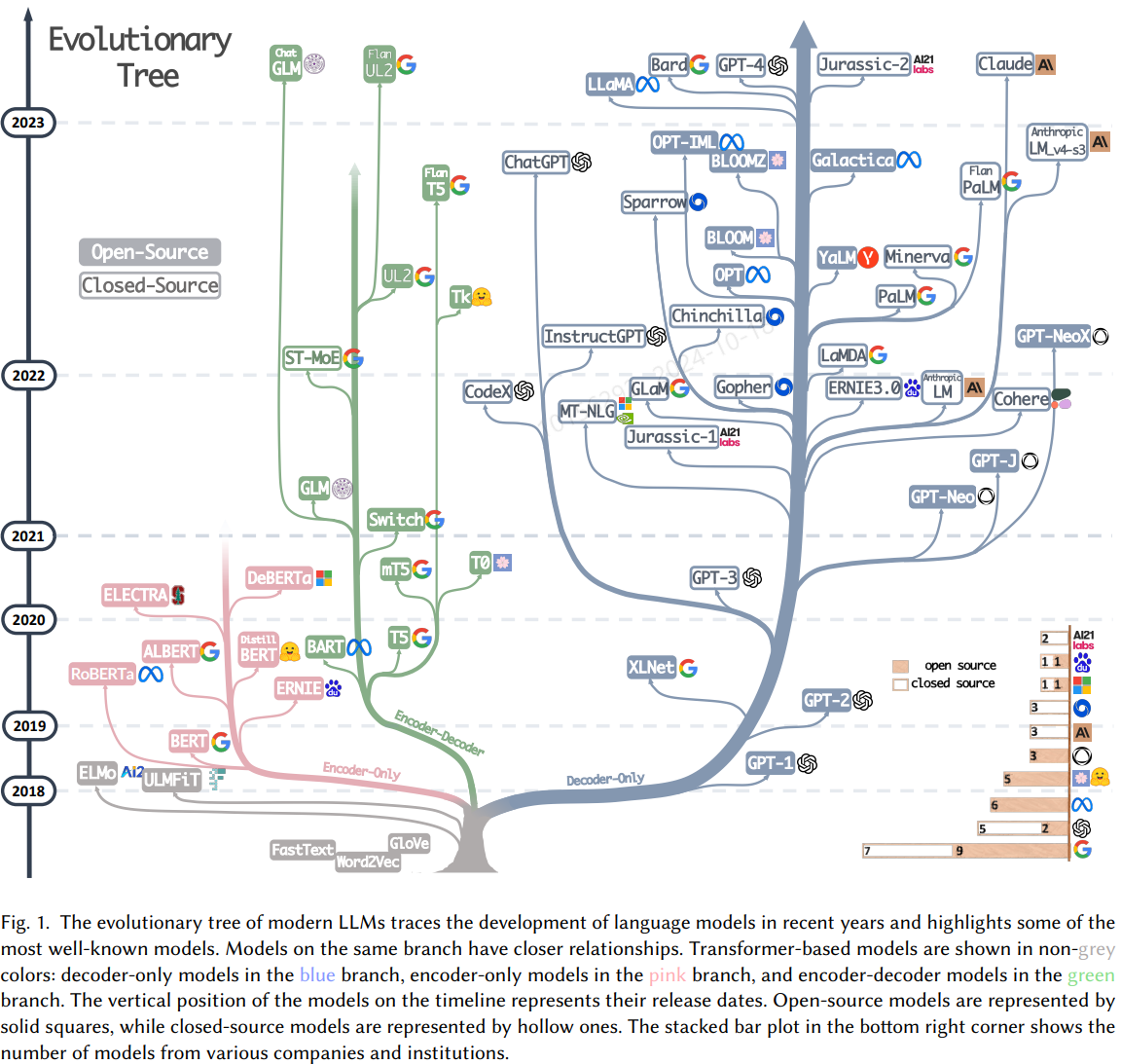
- Encoder-only: 우리 말을 기계가 잘 이해할 수 있게끔 만드는 데 집중한 모델
- 텍스트 내 문맥 파악과 분석 → 문서 분류, 감정분석, 검색 시스템 등에 많이 사용됨.
- BERT, RoBERTa, ALBERT 등
- Decoder-only: 우리가 말을 했을 때 답하는 역할을 잘 하는 모델
- 텍스트 생성 → 언어 생성, 대화 모델에 많이 사용됨.
- GPT 등
- Encoder-Decoder: 우리 말을 이해하고 답하는 것 모두 잘 하는 모델
- 텍스트의 이해와 생성 → 번역, 요약 등의 작업에 많이 사용됨.
- T5, BART, mBART 등
참조
- (논문) Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond
- (논문) Attention is All You Need
- https://news.skhynix.co.kr/post/all-around-ai-1
- https://jalammar.github.io/illustrated-transformer/
- https://www.youtube.com/watch?v=mxGCEWOxfe8
- https://medium.com/@fareedkhandev/understanding-transformers-a-step-by-step-math-example-part-1-a7809015150a
- https://poloclub.github.io/transformer-explainer/
728x90
'📓 Papers' 카테고리의 다른 글
| From Local to Global: A Graph RAG Approach to Query-Focused Summarization (0) | 2024.10.22 |
|---|---|
| Learning Single Camera Depth Estimation using Dual-Pixels (0) | 2021.10.03 |
| HITNet: Hierarchical Iterative Tile Refinement Network for Real-time Stereo Matching (0) | 2021.10.03 |
| SIMPLE ONLINE AND REALTIME TRACKING (0) | 2021.10.03 |
| YOLOv4: Optimal Speed and Accuracy of Object Detection (0) | 2021.10.03 |