Abstract
a huge number of features → to improve CNN accuracy
- YOLO v4 - use new features and achieve state-of -the-art results.2) CSP (Cross-Stage-Partial-Connections)4) SAT (Self-Adversarial-Training)6) Mosaic Data Agumentation8) CIOU Loss
- 7) Drop Block Regularization
- 5) Mish Activation
- 3) CmBN (Cross mini-Batch Normalizations)
- 1) WRC (Weighted-Residual-Connections)
⇒ acheive: MS COCO dataset AP: 43,5%, 65 FPS(realtime)
1. Introduction
Problem
The most accurate modern NN
- do not operate in real time
- require large number of GPUs for training with large mini-batch-size
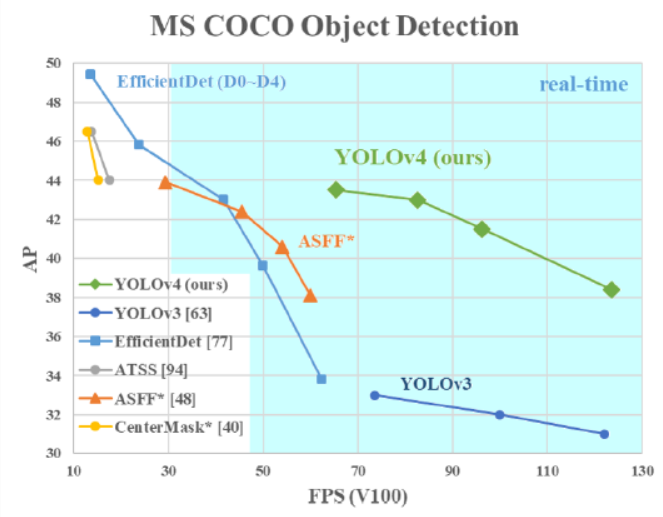
- Figure 1. YOLO v4 vs. state-of-the-art object detectors
- YOLO v4 vs. EfficientDet: comparable performance, x2 faster FPS
- improve YOLO v3's AP 10%, FP 12%
contributions
- efficient and powerful object detection model
- verify the influence of BoF and BoS methods during training
- modify state-of-the-art methods more effecient and suitable for single GPU training
2. Related Work
2.1 Object detection models
- backbone: pre-trained on ImageNet
- neck: collect featuremaps from each stages
- head: class + bounding box prediction
- Dense Prediction(one-stage)
- Sparse Prediction(two-stage)
: class prediction, bounding box regression 부분이 분리
2.2 Bag of freebies(BOF)
: methods that only change training strategy or only increase training cost
⇒ better accuracy without increasing inference cost
- Data augmentation
- photometric or geometric distortions
- CutOut
- CutMix
- Regularization
- DropOut
- DropPath
- Spatial DropOut
- DropBlock
- Objective function of BBox Regression: Loss function
- MSE
- IoU
- GIoU, CIoU, DIoU
2.3 Bag of Specials(BOS)
: plugin modules or post-processing(후처리) methods that increase the inference cost (small) + significantly improve the accuracy
- enhance receptive field
: SPP, ASPP, RFB - attention module
: SE(Squeeze and Excitation), SAM(Spatial attention module) - feature integration
- skip connection, hyper-column
- SFAM(SE), ASFF(softmax), BiFPN(multi-input weighted residual connections)
- good activation function
- ReLU
- LReLU, PReLU
- SELU
- Swish, hard-Swish
- Mish
- post-processing → no longer required in anchor-free
- NMS(Non-Maximum Suppression): optimize the objective function
3. Methodology
fast operating speed of neural net + optimization for parallel computations
3.1 Selection of architecture
Objective
- optimal balance among the network resolution, convolution layer number, parameter number, layer outputs number
- select additional blocks for increasing the receptive field
and best parameter aggregation
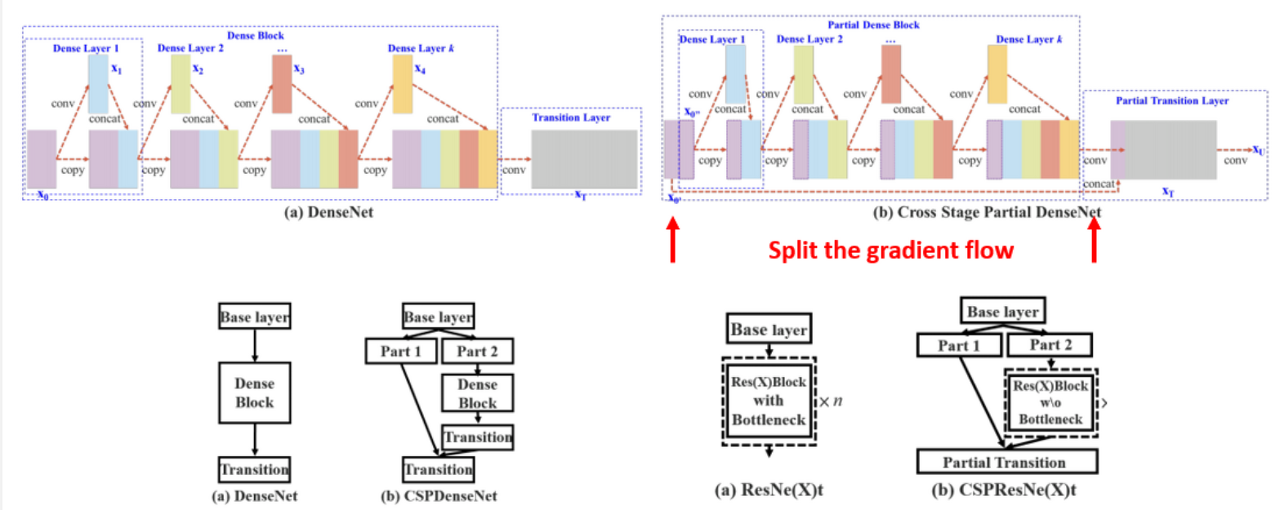
CSPNet
→ design and use a CSPNet based backbone
- propose Cross Stage Partial Network structure
: reduce extremely heavy inference cost and minimize accuracy loss - Figure: CSPNet based backbone architecture: After dividing input feature map into 2 parts, one part doesn't participate in the operation and then merges into output.
- → reduce the inference cost, memory cost, etc.
- detector requires...
- YOLO의 문제 : 작은 object에 취약하다. → 다양한 작은 object를 잘 검출하기 위해 input resolution을 크게 사용했다.
- receptive field를 물리적으로 키워주기 위해 layer 수를 늘림
- 하나의 image에서 다양한 종류, 다양한 크기의 object들을 동시에 검출하려면 높은 표현력이 필요하므로 paraeters 수를 늘림
- higher input network resolution
: detect multiple small-sized objects - more layers
: higher receptive field (increased size of input network) - more parmeters
: to detect multiple objects of different sizes in a single image - larger receptive field, larger number of parameters → backbone.
- CSPDarknet53: larger receptive field, larger number of parameter, FPS fastest
- CSPDarknet53 → optimal backbone for a detector!

YOLOv4 > CSPDarknet53
- additional blocks: SPP block
- increase receptive field
- separate out the context feature
- no reduction of the network operating speed
- parameter aggregation: PAN
- YOLOv3: FPN
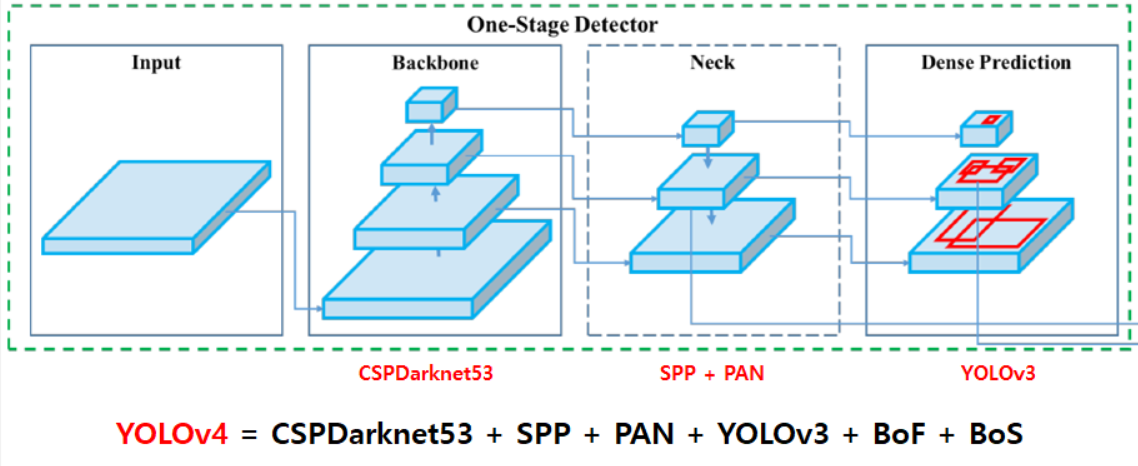
📌 Final architecture
- backbone: CSPDarknet53
- neck:
- additional blocks: SPP(Spational Pyramid Pooling)
- path-aggregation: PANet(Path Aggregation Network)
- head: YOLOv3
3.2 Selection of BoF and BoS
- BoF
- Bounding box regression loss: MSE, IoU, GIoU, CIoU, DIoU
- Data augmentation: CutOut, MixUp, CutMix
- Regularization method:
DropOut, DropPath, Spatial DropOut, DropBlock
- BoS
- Activations: ReLu, leaky-ReLu,
Swish, Mish→ ReLU6: for quantization network
PReLU, ReLU6, SELU, - → PReLU, SELU: difficult to train
- Normalization of the network activations by their mean and variance
: BN,, FRN(Filter Response Normalization), CBN(Cross-Iteration Batch Normalization)CGBN(or SyncBN) - → single GPU
- Skip-connections: Residual connections, Weighted residual connections, Multi-input weighted residual connections, Cross stage partial connections (CSP)
- Activations: ReLu, leaky-ReLu,
3.3 Additional improvements
: designed and improved the detector more suitable for training on single GPU
- introduce new method of data augmentation
- Mosaic, SAT
- select optimal hyper-parameters: genetic algorithms
- modify existing methods → suitable for efficient training and detection
- modified SAM, modified PAN, CmBN
BOF
- Mosaic
- : mix 4 trainining images

- detect objects outside normal context
- batch normalization
: calculate activation statistics from 4 images on each layer - → reduce the need for large mini-batch size
- SAT (Self-Adversarial Training)
- alter the original image
- adversarial attack (itself)
- train the neural network to detect an object on this modified image in the noraml way
- alter the original image
- : 2 forward backward stages
BOS
- CmBN
- Figure 4: Cross mini-Batch Normalization
-

- collect statistics only between mini-batches within a single batch
- modified SAM
- spatial-wise attention → point-wise attention
- Figure 5: Modified SAM
-

- modified PAN
- PAN's shortcut connection → concatenation (replace)
- Figure 6: Modified PAN
-

3.4 YOLOv4
YOLOv4
- Backbone: CSPDarknet53
- Neck: SPP, PAN
- Head: YOLOv3
BOF
- backbone
- data augmentation: CutMix, Mosaic
- imbalance sampling: Class labeling smoothing
- Regularization: DropBlock
- detector
- objective function: CIoU-loss
- normalization of network activation: CmBN
- regularization: DropBlock
- data augmentation: Mosaic, SAT
- hyper-parameters optimization: Genetic algorithms
- learning rate scheduler: Cosine annealing scheduler
- 기타:
- eliminate grid sensitivity
- use multiple anchors for a single ground truth
- random training shapes
BOS
- backbone
- activation: Mish
- skip connections: CSP, MiWRC
- detector
- activation: Mish
- receptive field enchancement: SPP
- attention: modified SAM
- feature integration: modified PAN
- post-processing: DIoU-NMS
4. Experiments
4.1 Experimental SetUp
4.2 Influence of different features on Classifier training
features
- Class label smoothing
- data augmentation
: bilateral blurring, MixUp, CutMix, Mosaic - activations
: Leaky-ReLU(by default), Swish, Mish
Result
- improve accuracy
- BoF-backbone: CutMix, Mosaic, Class label smoothing
- additional option: Mish

4.3 Influence of different feature on Detector training
BOF
- 1) BOF
- loss: MSE 고정

- M, GA, CBN, CA → good performance
- 2) BOF: S, M, IT, GA
- loss: GIoU, DIoU, CIoU

- S, M, IT, GA + CIoU → improve performance
- 3) OA(Optimized Anchors)
- CIoU + S, M, IT, GA

- OA → improve performance
- 4) Loss
- Loss: MSE, GIoU, CIoU

- GIoU, CIoU → high performance
BOS
- backbone: CSPResNeXt50
- features
- : PAN, RFB, SAM, Gaussian YOLO (G), ASFF

- SPP + PAN + SAM → BEST
4.4 Influence of different backbones and pre-trained weightings on Detector training
: the influence of different backbone models on the detector accuracy
- best classification accuracy model is not always the best detector accuracy model.
- CSPResNexT50: classifier
- BoF, Mish + CSPResNeXT50
: increase classifier, decrease detector acc
- BoF, Mish + CSPResNeXT50
- CSPDarknet53: detector
- BoF, Mish + CSPDarknet53
: increase both accuracy - more suitable for detector
- BoF, Mish + CSPDarknet53
4.5 Influence of different mini-batch size on Detector training
: compare the results of models trained with different mini-batch sizes.
- After BoF, BoS, mini-batch size → no effect on the detector's performance
- ⇒ After BoF, BoS, no need for expensive GPUs
5. Results
- Figure 8: comparison of the speed and accuracy of object detectors
-

YOLOv4
- located on the Pareto optimality curve
- superior in speed + accuracy
6. Conclusion
- faster(FPS), more accurate(MS COCO AP50...95, AP50) detector
- be trained and used on a conventional GPU with 8 to 16 GB VRAM → broad use
- one-stage anchor-based detector의 viability 입증
- verify features/ select features that improve the accuracy of bot classifier and detector